User Guide
This website allows you to navigate and query the CLaSSES database. Two languages are available, Italian and English: you can select either of them in the initial page of the site.
In this guide you will learn:
- How to perform basic queries
- How to perform an advanced search
- How to get more information and export data
How to perform basic queries
The corpus CLaSSES can be fully accessed by clicking the Search button and selecting the corpus of interest: Rome and Italy, Roman Britain, Egypt and Eastern Mediterranean or Sardinia. It is also possible to search the whole corpus by selecting Advanced search (for registered users only; see below). The sections can be also accessed from the map in the Homepage, which shows the number and the geograohic disctribution of the texts included in the database. All the words contained in each corpus are reported, together with information about the language, the typology of the inscription or the letter, its dating, its place of provenance, and many linguistic features (see below for further details). It is possible to use and combine search filters to perform simple queries on the corpus selected by using the drop-down buttons in the upper part of the page:
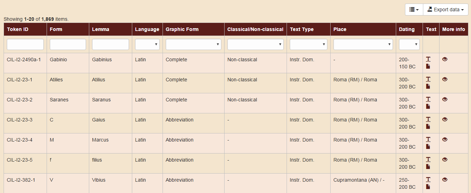
Figure 1. The query options available in the Search page.
If you leave one or more buttons empty (which is the default option), the system will not filter the results.
Token ID: this is the identification code associated to each form of the corpus selected. It contains the volume of the reference edition (e.g. CIL I2), the number of the inscription, and the position in which the token occurs within it. In order to search for a particular inscription, just type its number as it appears in the volume of the reference edition (e.g. in the section Rome and Italy “398” will return the epigraph CIL I2, 398) in this search box.
Form: it allows you to search for the occurrences of an exact word form in the corpus selected. For instance, if you type the word dede in this search box, the query system will return all occurrences of the exact form dede. You may also use the following jolly characters (which may also be combined):
- * stands for zero or more occurrences of whichever character. E.g. dede* will return dede, dederon, dedet, etc.
- ? stands for a single occurrence of a character. E.g. ded? will return dede, dedi, but not dedet
Lemma: it allows you to search for all the forms occurring in epigraphic texts that have been annotated with a specific lemma. Obviously, words and abbreviations that cannot be fully understood were not lemmatised. You should search by citation form, i.e. writing a word in the search box “lemma” using the nominative singular for nouns and adjectives, and the first person singular, present indicative for verbs. For instance, if you write in this tab do (“I give”), the query system will return all occurrences of the verb do, such as dede, dedit, dedron, etc.
Language: it allows you to focus your research only on words belonging to specific languages, such as Latin, Greek, Oscan, Iberian, Umbrian, Etruscan, etc. Moreover, mixed forms (e.g. Latin/Greek) are marked as Hybrid, whereas those of unknown language are marked as Unknown. Forms of uncertain language can be searched by selecting “-”.
Graphic form: it allows you to select forms on the basis of their conservation status:
- Complete, e.g. Diana
- Incomplete, for words partially integrated by editors, such as Me[nervae], or impossible to integrate, such as octav[...]
- Completely integrated by editors, e.g. [lapis]
- Abbreviations, i.e. shortenings, such as personal name initials, or don for donum
- Uncertain, for words that cannot be interpreted, not even in their graphical form, e.g. striando
- Presumed misspellings, e.g. Cudido for Cupido
- Roman numbers
- Lacunae
- Symbol (only in the section Roman Britain), for non-alphabetical signs appearing in the texts. These are presented in CLaSSES not as graphic signs, as they actually appear in letters, but with an indication of their meaning between brackets, e.g. symbol(denarii).
Classical/Non-classical: it allows you to focus your research only on Latin words that can be clearly considered as “non-classical” (i.e. forms that do not belong to the tradition of Classical Latin), or on the classical ones. For instance, if you select “non-classical”, the query system will return forms such as dede and Cornelio, whereas if you select “classical” it will return forms such as dedit and Cornelius. Forms that cannot be classified according to this parameter (i.e. non-Latin words, initials, forms that are completely integrated by editors or that cannot be interpreted) can be searched by selecting “-”.
More information on such classification may be found in the references cited in the Documentation page.
Text type/epistolary typology: it allows you to search for all the forms occurring in epigraphic texts or letters of a specific text type. For the sections Rome and Italy and Sardinia, text types are the following: tituli honorari (honorary inscriptions dedicated by public figures and monumental inscriptions), tituli sepulcrales (commemorative inscriptions and epitaphs), instrumenta domestica (inscriptions on everyday objects), tituli sacri publici (votive inscriptions dedicated by public figures) and tituli sacri privati (votive inscriptions dedicated by private customers). For the section Roman Britain, text types are the following: military reports (communication between officers regarding the activity of the garrison), commeatus (application of leave to the prefect of the cohort), numera (accounts of various types), memorandum (short communication left by one garrison to the other), commendatio (letters of reccomendations), literaria (writing exercises), miscellany (whose attribution is uncertain, but the text is readable), and descripta (whose text is too faded for reading a whole word without doubts about its reconstructions). For the section Egypt and Eastern Mediterranean, epistolary genre has been annotated adopting the distinction between formal (i.e. public) and informal letters (i.e. private letters of information).
Place: it allows you to limit your search only to texts of a specific place of provenance (only for Rome and Italy, Egypt and Eastern Mediterranean and Sardinia, since all the texts contained in the section Roman Britain are from Vindolanda). All toponyms can be seen by clicking the drop-down button and are reported in both the Italian (with the province abbreviation) and the Latin form, when possible (e.g. Fabrica di Roma (VT) / Falerii Novi). When you select “-” (the second choice in the drop-down button, after the empty field for the no-filter option), the query system will return all forms of epigraphic texts of uncertain origin. In a few cases, in the drop-down menu you will find provenance places indicated by an Italian name, without any (or with unknown) corresponding Latin toponym (e.g. Corleone (PA) / -).
Dating from / dating to: these search functions allow you to consider only texts of a specific chronological period. For the years befor Christ, the number of the year has to come after a dash (e.g. "-150" for 150 BC, "150" for 150 AD).
Author: this search function is only in the section Roman Britain (which contains letters), and allows you to select texts written by a precise author.
Addressee: this search function is only in the section Roman Britain and allows you to select texts addressed to a precise person.
Support material: this search function is only in the section Egypt and Eastern Mediterranean and allows you to select letters written on ostrakon or papyrus.
How to perform an advanced search
After registering on the website (through the Register page) and logging in, you can access the advanced search options.
Advanced search: by clicking on the Search button and selecting Advanced search from the drop-down menu, you can search the whole corpus, and not just a single section.
Advanced use of filters: after selecting the corpus of interest (or the Advanced search option to search the whole corpus), it is possible to select more than one option for every filter described in the previous section (e.g. Language: Latin + Greek + hybrid), as well as to combine several filters (e.g. Language: Etruscan + Graphic form: complete).
Linguistic phenomena: through these filters it is possible to search the CLaSSES corpus focusing on specific phenomena of orthographic variation related to:
- Vowels: e.g. phenomena of vowel alternation, phenomena related to diphthongs, phenomena concerning vowel length, or omission or insertion of vowels;
- Consonants: e.g. phenomena of consonant insertion, doubling or omission in the central or final position of a word;
- Morphophonology: variation phenomena occurring in morphophonological position, e.g. in nominal or verbal endings.
How to get more information and export data
When you have selected the forms of interest with the filter options, you can access further information. For each form of the corpus, on the rightmost part of the page you will find the Text and More info columns.
Text: in this column there are no filter options, but you will find two symbols: the first one allows to access the context in which each form of the corpus occur (5 words before/after), and the second one to read the entire inscription.
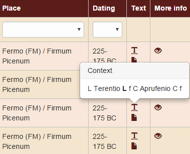
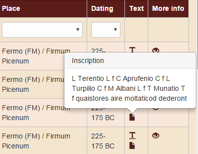
Figure 2. Visualizing the context and the entire inscription.
More info: if you click on the symbol of the eye, a new page will open which all information related to a given form are reported. In this section, all the data reported in the Search page are summarised (token ID, form, language, graphic form, lemma, classical/non-classical, text typology, place, author, addressee, dating, context, and entire inscription). In addition, for non-classical forms, you will also read the equivalent classical form (for instance, consul for non-classical cosol). At the end of the page, the variation linguistic phenomena individuated for that form, which characterize it as non-classical, are reported. Such variation phenomena may be related to vowels, consonants, or morphophonology.
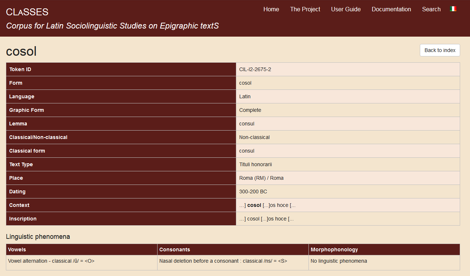
Figure 3. The section More info.
LiLa: each lemmatized token displays a white logo under the heading ‘LiLa’, in the very last column in each row. By clicking on this logo, you will be redirected to the lemma included in LiLa – Knowledge Base of Interoperable Linguistic Resources for Latin, a collection of both lexical and textual resources for Latin (corpora, lexica, ontologies, dictionaries, thesauri) made interoperable following the principles of the Linked Data paradigm. In this way, you can access information concerning the occurrences of the lemma in other lexical and textual Latin sources.
Export data: with the Export options in the Search page you can export, at any moment, the data you have searched for. With two drop-down menu you can select the kind of data you are interested in exporting, as well as the export format (CSV, Text, Excel 1995 +, Excel 2007 +).

Figure 4. The Export data buttons.