Guida utente
Questo sito, disponibile in due lingue (italiano e inglese), permette di esplorare e consultare il database CLaSSES. La Guida Utente contiene istruzioni su:
- Come effettuare una ricerca semplice
- Come effettuare una ricerca avanzata
- Come ottenere ulteriori informazioni ed esportare i dati
Come effettuare una ricerca semplice
Il database CLaSSES può essere interrogato cliccando sul pulsante Ricerca e selezionando dal menù a tendina il corpus di interesse: Roma e l'Italia, Britannia romana, Egitto e Mediterraneo orientale o Sardegna. Inoltre, è possibile interrogare l'intero corpus selezionando l'opzione di Ricerca avanzata dal menù a tendina (solo per utenti registrati; vd. sotto). Le quattro sezioni sono accessibili anche dalla mappa presente nella Homepage, che mostra il numero e la distribuzione geografica dei testi considerati. Per ciascun corpus, viene mostrato l'elenco delle parole che lo compongono, ordinate per epigrafe o lettera, insieme a numerose altre informazioni relative alla lingua delle singole forme, la tipologia, il luogo di ritrovamento del reperto e la sua datazione, così come anche diversi dati di carattere linguistico (vedi oltre).
È possibile effettuare una ricerca semplice all’interno del corpus selezionato attraverso i menù a tendina nella parte superiore della pagina:
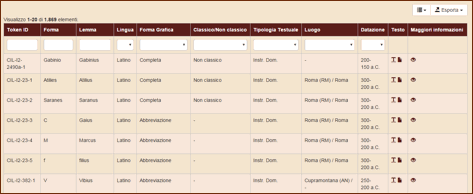
Figura 1. Le opzioni accessibili dalla pagina Ricerca.
Se uno o più campi vengono lasciati vuoti (come nell’opzione di default), i risultati non verranno filtrati.
Token ID: è il codice identificativo associato a ciascuna forma del corpus. Contiene il volume dell’edizione di riferimento (ad es. CIL I2), il numero dell’iscrizione e la posizione che la forma occupa all’interno dell’epigrafe o della lettera. Per cercare una particolare iscrizione, bisogna inserire nel campo di ricerca il numero ad essa associato nell’edizione di riferimento (ad es. “398”, nelle sezione Roma e l'Italia, rimanda all’epigrafe CIL I2, 398).
Forma: permette di cercare le occorrenze di una forma esatta all’interno del corpus selezionato. Ad esempio, digitando in questo campo dede, il sistema di ricerca riporterà tutte le occorrenze della forma esatta dede. È possibile utilizzare (anche in combinazione) i seguenti caratteri jolly:
- * corrisponde a zero o più occorrenze di un qualsiasi carattere. Ad es. la ricerca dede* riporterà le forme dede, dederon, dedet, ecc.
- ? corrisponde alla sigola occorrenza di un qualsiasi carattere. Ad es. la ricerca ded? riporterà le forme dede, dedi, ma non dedet.
Lemma: permette di ricercare tutte le forme del corpus selezionato che corrispondono a un dato lemma. Ovviamente, le parole e le abbreviazioni che non possono essere interpretate con sicurezza non sono state lemmatizzate. Nel campo di ricerca Lemma bisogna inserire la forma di citazione, ovvero il nominativo singolare nel caso di nomi e aggettivi, e l’indicativo presente della prima persona singolare nel caso di verbi. Ad esempio, digitando in questo campo do (“io do”), il sistema di ricerca riporterà tutte le occorrenze del verbo do, come dede, dedit, dedron, ecc.
Lingua: permette di focalizzare la ricerca soltanto sulle forme di una particolare lingua, come latino, greco, iberico, osco, umbro, etrusco, ecc. In aggiunta, si sono distinte le forme ibride (ovvero miste) e quelle di lingua ignota (ovvero sconosciuta). È possibile cercare le forme di lingua incerta selezionando “-”.
Forma grafica: permette di filtrare le forme sulla base del loro stato di conservazione:
- Completa, come per Diana
- Incompleta, per parole parzialmente integrate dell’editore, come Me[nervae], o non integrabili, come octav[...]
- Completamente integrata dall’editore, come per [lapis]
- Abbreviazioni, come per le iniziali di nomi propri, o don per donum
- Incerta, per forme che non sono interpretabili neppure nella loro forma grafica, come striando
- Presunti errori grafici, come Cudido for Cupido
- Numeri romani
- Lacunae
- Simbolo (solo per la sezione Britannia romana), in riferimento ai vari segni grafici, non alfabetici, riscontrati nei testi. Il testo proposto non riporta i simboli nella loro forma originaria, ma ne indica il significato tra parentesi tonde, ad es. symbol(denarii).
Classico/Non classico: permette di focalizzare la ricerca solo sulle parole latine che possono essere interpretate chiaramente come “non classiche” (ovvero, non appartenenti alla tradizione del latino classico), oppure solo su quelle interpretabili come “classiche”. Ad esempio, selezionando dal menù a tendina “non classico”, il sistema riporterà forme come dede e Cornelio, mentre selezionando “classico” riporterà forme come dedit e Cornelius. Selezionando “-”, il sistema ricercherà invece quelle forme che non possono essere classificate sulla base di questo parametro (ad esempio parole non latine, iniziali, parole completamente integrate dall’editore o che non possono essere interpretate). Maggiori informazioni su tale classificazione sono reperibili nelle pubblicazioni citate nella pagina Documentazione.
Tipologia testuale/epistolare: permette di cercare solo le forme appartenenti ad epigrafi o lettere di una data tipologia testuale. Le tipologie testuali utilizzate per le sezioni Roma e l'Italia e Sardegna sono le seguenti: tituli honorarii (iscrizioni celebrative di personaggi pubblici e iscrizioni monumentali), tituli sepulcrales (epitafi e iscrizioni commemorative), instrumentum domesticum (iscrizioni su oggetti di uso quotidiano e altri supporti mobili), tituli sacri publici (iscrizioni votive dedicate da personaggi pubblici) e tituli sacri privati (iscrizioni votive dedicate da committenti privati). Per la sezione Britannia romana le tipologie considerate sono invece: resoconto militare (comunicazioni tra ufficiali della guarnigione e concernenti l’attività del forte), commeatus (richieste di permesso, inviate al prefetto della coorte), numera (liste di vario genere), memorandum (promemoria lasciati da una guarnigione a quella subentrante), commendatio (lettere di raccomandazione), literaria (esercizi di scrittura), miscellanea (testi per i quali non si può stabilire una tipologia testuale certa) e descripta (testi nei quali l’inchiostro è troppo sbiadito per poter leggere con certezza anche solo una parola per intero senza avere dubbi sulla sua ricostruzione). Per la sezione Egitto e Mediterraneo orientale si è distinto tra tra lettera formale (in cui rientrano le varie tipologie di lettere pubbliche) e lettera informale (in cui rientrano le lettere private di informazione).
Luogo: questa funzione di ricerca, presente solo per le sezioni Roma e l'Italia, Egitto e Mediterraneo orientale e Sardegna (dal momento che tutti i testi raccolti nella sezione Britannia romana provengono, al momento, dal forte di Vindolanda), permette di restringere la ricerca a uno specifico luogo di provenienza dell’epigrafe o lettera. L’intera lista di toponimi può essere visualizzata cliccando sul menù a tendina e, per ciascun luogo, è presente sia il nome in italiano (con l’abbreviazione della provincia), che la forma latina, quando ciò sia possibile (ad es. Fabrica di Roma (VT) / Falerii Novi). Selezionando “-” (la seconda scelta nel menù a tendina, dopo il campo vuoto per l’opzione “nessun filtro”), il sistema cercherà tutte le forme di origine incerta. In alcuni casi, nel menù a tendina, i luoghi sono indicati con un nome italiano senza però un corrispettivo latino, quando quest’ultimo non esista o non sia conosciuto (ad es. Corleone (PA) / -).
Datazione da / datazione a: queste due funzioni di ricerca permettono di selezionare testi di un preciso arco cronologico. Per gli anni precedenti l'era cristiana, è necessario premettere all'indicazione dell'anno un trattino (ad es. "-150" per l'anno 150 a.C., "150" per l'anno 150 d.C.).
Autore: questa funzione è presente solo per la sezione Britannia romana, contenente lettere, e permette di restringere la ricerca a testi redatti da un preciso autore.
Destinatario: questa funzione, anch'essa presente solo per la sezione Britannia romana, permette di restringere la ricerca a testi indirizzati ad un preciso destinatario.
Supporto: questa funzione è presente solo per la sezione Egitto e Mediterraneo orientale e permette di restringere la ricerca alle lettere su ostracon o papiro.
Come effettuare una ricerca avanzata
Dopo essersi registrati al sito (accessibile alla pagina Registrati) e aver effettuato il Login, è possibile accedere alle opzioni di ricerca avanzata.
Ricerca avanzata: cliccando sul pulsante Ricerca e selezionando Ricerca avanzata dal menù a tendina, è possibile effettuare una ricerca sull'intero corpus, e non solo su una singola sezione.
Utilizzo avanzato dei filtri: dopo aver selezionato il corpus di interesse (o l'opzione Ricerca avanzata per consultare l'intero corpus), è possibile selezionare più opzioni per ogni filtro di ricerca descritto nella sezione precedente (ad es. Lingua: latino + greco + ibrido), nonché combinare più filtri (ad es. Lingua: etrusco + Forma grafica: completa).
Fenomeni linguistici: attraverso questi filtri è possibile effettuare ricerche sul corpus CLaSSES focalizzate su specifici fenomeni di variazione ortografica relativi a:
- Vocalismo: ad esempio, fenomeni di alternanza vocalica, fenomeni relativi ai dittonghi, fenomeni riguardanti la lunghezza vocalica, o l'omissione o l'inserzione di vocali;
- Consonantismo: ad esempio, fenomeni di inserzione, raddoppiamento, od omissione di consonanti in posizione centrale o finale di parola;
- Morfofonologia: fenomeni di variazione che ricorrono in posizione morfofonologica, ad esempio nelle desinenze nominali o verbali.
Come ottenere ulteriori informazioni ed esportare i dati
Una volta selezionate le forme di interesse con l’utilizzo dei filtri, è possibile accedere ad ulteriori informazioni, grazie alle colonne Testo e Maggiori informazioni: presenti nella parte destra della pagina.
Testo: questa colonna non viene utilizzata per filtrare i dati, ma contiene due simboli: il primo permette di visualizzare il contesto di occorrenza di ciascuna forma del corpus (5 parole prima/dopo), mentre il secondo permette di visualizzare l'intera iscrizione in cui essa è contenuta.
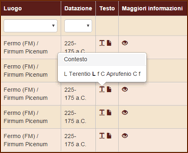
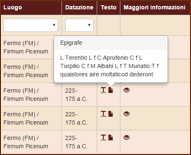
Figura 2. La visualizzazione del contesto e dell’epigrafe di appartenenza.
Maggiori informazioni: cliccando sul simbolo dell’occhio che appare nella penultima colonna, si aprirà una nuova pagina in cui vengono riportate tutte le informazioni relative ad una data forma. In questa sezione, vengono innanzitutto riassunti tutti i dati già presentati nella pagina di ricerca (token ID, forma, lingua, forma grafica, lemma, classico/non classico, tipologia testuale, luogo, autore, destinatario, datazione, contesto e intera iscrizione).
Inoltre, solo nel caso di forma non classica, viene visualizzata anche l’equivalente forma classica (ad esempio, consul per il non classico cosol) e, in fondo alla pagina, i fenomeni di variazione linguistica per cui tale forma è stata classificata come non classica. Tali fenomeni di variazione linguistica possono riguardare il sistema vocalico, quello consonantico, o la morfofonologia.
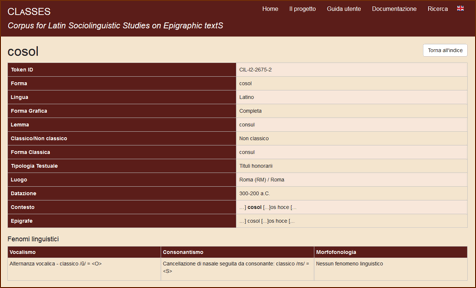
Figura 3. La sezione Maggiori informazioni.
LiLa: cliccando sul logo bianco nell’ultima colonna della pagina, disponibile per le forme lemmatizzate, si aprirà un link al relativo lemma presente in LiLa - Knowledge Base of Interoperable Linguistic Resources for Latin, una raccolta interoperabile di banche dati che include risorse lessicali e testuali per lo studio del latino secondo il modello dei Linked Open Data. In questo modo, è possibile ottenere informazioni circa le occorrenze del lemma in altre risorse testuali e lessicali.
Esporta: Dalla pagina Ricerca, è possibile esportare in ogni momento i dati visualizzati grazie a due menù a tendina, che permettono di scegliere il tipo di dati da esportare (datazione, lingua, lemma ecc.) e il formato di esportazione (CSV, Text, Excel 1995 +, Excel 2007 +).

Figura 4. I pulsanti per l’esportazione dei dati.